Engineering brief
AI Dev 26 x SF | Ara Khan: Evals Are Broken Use Them Anyway
The Brief
Agent evals are noisy and gamed; use task-specific, containerized evals to tune harnesses, choose models, and control cost.
Decision relevance
Read this for workflow impact, implementation trade-offs, and the claims that need technical scrutiny before they reach team planning.
Summary
The talk argues that both extremes—trusting leaderboard numbers and relying on “vibes”—mislead teams about model quality. Instead, treat evals as decision-support, not truth. Generic benchmarks (ELO, SWE-bench) are saturated and easily gamed; lab-published numbers often reflect benchmark optimization, not real-world behavior.
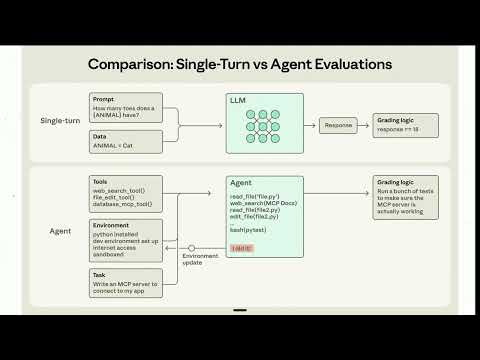
What matters is task-specific, agentic evals that mirror your workflows. For coding agents, TerminalBench-style tests run full multi-step sessions in isolated containers and grade outcomes with real unit tests. This surfaces practical metrics—turns, tool calls, tokens, wall time, and pass/fail—so you can quantify tradeoffs among quality, latency, and spend. Parallel, containerized runs (e.g., via Harbor/Modal) make this feasible operationally and reduce interference across tasks.
Crucially, evals test three things: the model, your agent harness (tooling, prompts, retries, timeouts), and the task framing. Many failures are harness issues, not model defects. Teams often discover they can beat a competitor’s results on the same model by tuning scaffolding and resource limits, not by swapping models. Cheap models may clear thresholds when the harness is disciplined.
Adoption guidance: stay current but avoid first-mover churn; wait weeks post-release before standardizing. Pick or build evals that map to your domain (not toy algorithms). Track total cost and latency, then set gates for model updates. Beware overfitting to the eval suite—use holdouts and “vibe checks” with real workflows to avoid cargo-cult improvements.
Caveats: claims of outscoring Claude Code are anecdotal and context-bound. The approach demands infra investment, careful containerization, and ongoing maintenance of tasks. But for teams shipping agentic systems, this is the pragmatic path that changes architecture and budgeting decisions.
Why It Matters
Model leaderboards mislead. Real gains come from harness, environment, and cost tracking. Proper evals drive architecture, budget, and model selection decisions.
Editorial analysis
Key claims
- Evals are imperfect; build/run your own, tied to your tasks, to steer agents and spending.
Practical use cases
- Use this as input for tooling evaluation, workflow planning, and technical due diligence.
Risks / caveats
- Lab-published benchmark scores and vibe-based “this model feels nice” takes.
Who should care
- Engineering managers, tech leads, and CTOs evaluating AI or developer tooling decisions.
Related topics
Bottom Line
Evals are imperfect; build/run your own, tied to your tasks, to steer agents and spending.
Watch
This video is blocked due to your privacy settings. To watch this video, please accept YouTube marketing cookies.
Related breakdowns
The agent-ready web: Simplify user actions with WebMCP — Tara Agyemang, Google
A short briefing on the practical engineering implications, trade-offs, and claims worth ignoring.
Don't use Fable 5 in Claude… do this instead
A short briefing on the practical engineering implications, trade-offs, and claims worth ignoring.
Build Agentic Ecommerce with KumoRFM
A short briefing on the practical engineering implications, trade-offs, and claims worth ignoring.
Get TL;DW
Too Long; Didn't Watch.
A concise breakdowns of the AI and devtools videos that actually matter for engineering leaders.
Free. Weekly. No hype.
Video and thumbnails remain the property of their respective creators. tldw.news provides editorial analysis, commentary, and discovery links to original content.